MERGE statement was a very useful addition which was introduced from SQL 2008. It is very useful in lots of day to day scenarios like normal UPSERT (UPDATE + INSERT) operations, slowly changing dimension processing etc.
This blog aims at explaining two not so common scenarios where MERGE statement comes handy.1. Generating an "Incremental" Data Population Script
In a typical project development there will be a need to create data scripts for populating generic values like configurations, master data entry, audit/ control table entries etc. During the course of the project the data scripts keeps on adding new values. In normal cases this will be handled by adding new INSERT scripts each time. So at the project end whilst doing the final migration to the production we will have a set of INSERT statements which may even span multiple files.
This can be replaced by a single MERGE statement to which we can always keep on adding values and executed in database to apply only the incremental changes.
The statement would look like below
MERGE INTO Table AS d
USING (VALUES('Value1','Value2',value3)) AS s (Col1, Col2, Col3)
ON s.Col1 = d.Col1
WHEN MATCHED
AND (
s.Col2 <> d.Col2
OR s.Col3 <> d.Col3
)
THEN
UPDATE SET Col2 = s.Col2, Col3 = s.Col3
WHEN NOT MATCHED
THEN
INSERT (Col1,Col2,Col3)
VALUES(s.Col1,s.Col2,s.Col3);
Illustration
Consider the code below
declare @t table
(
id int identity(1,1),
col1 varchar(50),
col2 varchar(50),
col3 int
)
MERGE @t AS d
USING (VALUES('Value1','Cat1',100),
('Value2','Cat1',150),
('Value1','Cat2',300),
('Value2','Cat2',225),
('Value3','Cat2',430),
('Value1','Cat3',520)
) AS s(col1,col2,col3)
ON s.col1 = d.col1
WHEN MATCHED
AND (
COALESCE(s.col2,'') <> COALESCE(d.col2,'')
OR COALESCE(s.col3,'') <> COALESCE(d.col3,'')
)
THEN
UPDATE
SET col2 = s.col2,col3= s.col3
WHEN NOT MATCHED BY TARGET
THEN
INSERT (col1,col2,col3)
VALUES(s.col1,s.col2,s.col3);
SELECT * FROM @t
Now suppose if you want to add three more values you can just extend that within same MERGE statement as below
declare @t table
(
id int identity(1,1),
col1 varchar(50),
col2 varchar(50),
col3 int
)
MERGE @t AS d
USING (VALUES('Value1','Cat1',100),
('Value2','Cat1',150),
('Value1','Cat2',300),
('Value2','Cat2',225),
('Value3','Cat2',430),
('Value1','Cat3',550),
('Value2','Cat3',610),
('Value1','Cat4',735),
('Value2','Cat4',821)
) AS s(col1,col2,col3)
ON s.col1 = d.col1
WHEN MATCHED
AND (
COALESCE(s.col2,'') <> COALESCE(d.col2,'')
OR COALESCE(s.col3,'') <> COALESCE(d.col3,'')
)
THEN
UPDATE
SET col2 = s.col2,col3= s.col3
WHEN NOT MATCHED BY TARGET
THEN
INSERT (col1,col2,col3)
VALUES(s.col1,s.col2,s.col3);
SELECT * FROM @t
I've marked the changed rows in green. I've added three new rows and changed the value of an existing row. Executing this you can see that only the incremental changes ie new rows + modified ones will get applied to table.You can keep on extending script like this and finally you'll just have a single MERGE statement in a single file with all values which you need to migrate to your production environment rather than a set of small small incremental INSERT scripts.
2. Populating Master Child Tables
Another major application of the MERGE statement comes in the cases where you want to populate a master child table with some external data. I had previously blogged about a similar scenario here
http://visakhm.blogspot.in/2010/04/using-xml-to-batch-load-master-child.html
Now lets see how MERGE statement can be used for achieving the same requirement. MERGE would provide a much more compact way of doing this without the need of any intermediate temporary table.
The XML looks like as in below file
https://drive.google.com/file/d/0B4ZDNhljf8tQbHdfZUFteXNRcDg/edit?usp=sharing
The tables can be given as below
declare @order table
(
OrderID int IDENTITY(100000,1),
OrderDesc varchar(1000),
OrderDate datetime,
CustomerDesc varchar(1000),
ShippedDate datetime,
WebOrder bit
)
declare @OrderItems table
(
OrderItemID int IDENTITY(1000,1),
OrderID int,
ItemDesc varchar(100),
Qty int,
ItemPrice decimal(15,2)
)
Nows lets see the illustration of how MERGE can be applied in the above scenario
Illustration
The code will look like below
INSERT INTO @OrderItems
(
OrderID,
ItemDesc,
Qty,
ItemPrice
)
SELECT *
FROM
(
MERGE INTO @order AS d
USING (SELECT t.u.value('OrderDesc[1]','varchar(100)') AS OrderDesc,
t.u.value('OrderDate[1]','datetime') AS OrderDate,
t.u.value('CustomerDesc[1]','varchar(1000)') AS CustomerDesc,
t.u.value('ShippedDate[1]','datetime') AS ShippedDate,
t.u.value('WebOrder[1]','bit') AS WebOrder,
m.n.value('ItemDesc[1]','varchar(100)') AS ItemDesc,
m.n.value('Qty[1]','int') AS Qty,
m.n.value('ItemPrice[1]','decimal(15,2)') AS ItemPrice
FROM @x.nodes('/Orders/Order')t(u)
CROSS APPLY u.nodes('OrderItem')m(n)) AS s
ON d.OrderDesc = s.OrderDesc
AND d.OrderDate = s.OrderDate
WHEN NOT MATCHED
THEN
INSERT (
OrderDesc ,
OrderDate ,
CustomerDesc ,
ShippedDate ,
WebOrder
)
VALUES
(
s.OrderDesc ,
s.OrderDate ,
s.CustomerDesc ,
s.ShippedDate ,
s.WebOrder
)
OUTPUT inserted.OrderID,
s.ItemDesc,
s.Qty,
s.ItemPrice
)t (OrderID,
ItemDesc,
Qty,
ItemPrice)
Now check the output and you can see the below
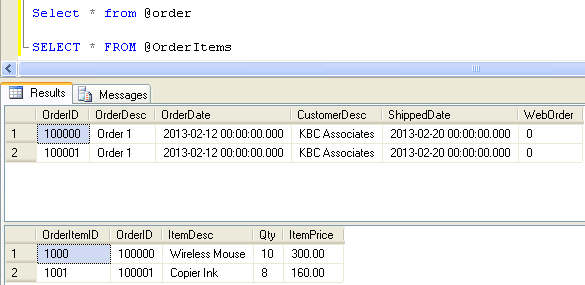
As seen above the data will get populated to the master and the child table preserving the referential integrity. This is made possible through the use of OUTPUT clause with MERGE. The OUTPUT clause when used with MERGE exposes the columns of source table/query in addition to the INSERTED and DELETED table columns which enables us to capture the generated id values from the parent table as well as all the required column values for the child table from the source query within the same statement. This is then used in a nested INSERT for populating the child table. This is a scenario where MERGE can come really handy to us.
Hope you enjoyed this article speaking about two not so common practical scenarios where MERGE can be applied. As always feel free to revert with your clarifications/comments.
Will be back with a new T-SQL tip soon!
No comments:
Post a Comment