In one of my recent data visualization projects I've had the need to generate the dense rank for a set of data after splitting them into horizontal groups. I've come up with the logic in DAX to find the dense rank among a group of data.
Consider the example of student details within a university where we need to rank students on the basis of total marks scored for each of the courses taken. We can think of sample data like below to illustrate it.
CREATE TABLE StudentDetails
(
StudentID int,
StudentName varchar(100),
SubjectName varchar(100),
Marks int,
CourseName varchar(100),
UniversityName varchar(100)
)
GO
INSERT StudentDetails
VALUES
(101,'Mary Thomas','Mechanics',89,'BS Computer Sc','University of Virginia'),
(112,'Keith Hudson','Control Systems',54,'BS Computer Sc','University of Virginia'),
(221,'Srinivasan Nagendran','Mechanics',78,'BS Computer Sc','University of Virginia'),
(101,'Mary Thomas','Microprocessors',77,'BS Computer Sc','University of Virginia'),
(115,'Harry Davis','Programming Techniques',72,'BS Computer Sc','University of Virginia'),
(112,'Keith Hudson','Queuing Models',91,'BS Computer Sc','University of Virginia'),
(2691,'Kennete James','Mechanics',75,'BS Computer Sc','Texas University'),
(1134,'Shari Kraskow','Control Systems',90,'BS Computer Sc','Texas University'),
(101,'Mary Thomas','Logic System Design',77,'BS Computer Sc','University of Virginia'),
(221,'Srinivasan Nagendran','Mathematics',98,'BS Computer Sc','University of Virginia'),
(2691,'Kennete James','Set Theory',85,'BS Computer Sc','Texas University'),
(115,'Harry Davis','Advanced Mathematics',92,'BS Computer Sc','University of Virginia'),
(1134,'Shari Kraskow','Advanced Modelling techniques',79,'BS Computer Sc','Texas University'),
(221,'Srinivasan Nagendran','Artificial Intelligence',63,'BS Computer Sc','University of Virginia'),
(1134,'Shari Kraskow','Algorithm Analysis',88,'BS Computer Sc','Texas University'),
(2691,'Kennete James','Logic Systems',78,'BS Computer Sc','Texas University')
Once the data is setup in the table we can import it to a power pivot sheet and calculate the dense rank values as shown below

As you see from above we've three calculated column added to the powerpivot. The first calculated column calculates the consolidated marks for each student for each of courses within the university. This is used as a basis for calculating the subsequent columns ie student rank within a university and overall rank.
The DAX functions used will be as follows
Student Total Marks
The DAX expression used is
=SUMX(FILTER(StudentDetails,EARLIER(StudentDetails[StudentName])=StudentDetails[StudentName] && EARLIER(StudentDetails[CourseName])=StudentDetails[CourseName] && EARLIER(StudentDetails[UniversityName])=StudentDetails[UniversityName] ),[Marks])
Lets analyze the above expression. FILTER() function will return us a derived table after applying a set of filter conditions over an existing table in powerpivot data model. EARLIER() is a rowcontext function available in DAX which puts current row value in context and does comparison based on that.
So FILTER(StudentDetails,EARLIER(StudentDetails[StudentName])=StudentDetails[StudentName] && EARLIER(StudentDetails[CourseName])=StudentDetails[CourseName] && EARLIER(StudentDetails[UniversityName])=StudentDetails[UniversityName] ) will compare values of StudentName,CourseName and UniversityName values of the current row with rest of the rows of the table and returns a derived table of matching rows. SUMX() will apply summation over specified column of the table passed. So in this case SUMX calculates the sum of Marks column within each of the table subset determined by values of StudentName,CourseName and UniversityName.
In example above for Mary Thomas rows it will return Total Marks as 89 + 77 + 77= 243 which is the consolidated value across all rows for the student.
Univ Course Student Rank
Expression is as follows
=CALCULATE(DISTINCTCOUNT(StudentDetails[Student Total Marks])+1,FILTER(StudentDetails,EARLIER(StudentDetails[CourseName])=StudentDetails[CourseName] && EARLIER(StudentDetails[UniversityName])=StudentDetails[UniversityName] && EARLIER(StudentDetails[Student Total Marks])< StudentDetails[Student Total Marks]))
This expression makes use of the same derived table logic to get subset of table for each row based on its CourseName,UniversityName values matching with current row value and having Total Marks values < the Total Marks value in the table. So this will return all rows for same course and university and having Student Total Marks value greater than the Total Marks for current row ie students above current student in terms of performance for same course and university. Because this table has subject level data we need to take distinct of this to get one row per student consolidated. Adding 1 to that will give current rank position of student with respect to total marks scored with same Course,University subset. CALCULATE() function calculates the given aggregate (in this case DISTINCTCOUNT +1 ) over the specified derived table returned by FILTER expression.
Overall Course Student Rank
This is exactly similar to the above with the only difference being we consolidate marks over CourseName field alone without considering university to get the overall rank value.
The above DAX expressions used are analogous to the below T-SQL logic
SELECT *,
DENSE_RANK() OVER (PARTITION BY CourseName,UniversityName ORDER BY StudentTotalMarks DESC) AS UnivCourseStudentRank,
DENSE_RANK() OVER (PARTITION BY CourseName ORDER BY StudentTotalMarks DESC) AS OverallCourseStudentRank
FROM
(
SELECT *,
SUM(Marks) OVER (PARTITION BY StudentName,CourseName,UniversityName) AS StudentTotalMarks
FROM StudentDetails
)t
If you run the above query against the database table and check results it should exactly match what we got inside the powerpivot sheet as below

You may refer the below links for more information on the DAX functions
EARLIER
http://technet.microsoft.com/en-us/library/ee634551(v=sql.105).aspx
CALCULATE
http://technet.microsoft.com/en-us/library/ee634825(v=sql.105).aspx
FILTER
http://technet.microsoft.com/en-us/library/ee634966(v=sql.105).aspx
SUMX
http://technet.microsoft.com/en-us/library/ee634959(v=sql.105).aspx
Consider the example of student details within a university where we need to rank students on the basis of total marks scored for each of the courses taken. We can think of sample data like below to illustrate it.
CREATE TABLE StudentDetails
(
StudentID int,
StudentName varchar(100),
SubjectName varchar(100),
Marks int,
CourseName varchar(100),
UniversityName varchar(100)
)
GO
INSERT StudentDetails
VALUES
(101,'Mary Thomas','Mechanics',89,'BS Computer Sc','University of Virginia'),
(112,'Keith Hudson','Control Systems',54,'BS Computer Sc','University of Virginia'),
(221,'Srinivasan Nagendran','Mechanics',78,'BS Computer Sc','University of Virginia'),
(101,'Mary Thomas','Microprocessors',77,'BS Computer Sc','University of Virginia'),
(115,'Harry Davis','Programming Techniques',72,'BS Computer Sc','University of Virginia'),
(112,'Keith Hudson','Queuing Models',91,'BS Computer Sc','University of Virginia'),
(2691,'Kennete James','Mechanics',75,'BS Computer Sc','Texas University'),
(1134,'Shari Kraskow','Control Systems',90,'BS Computer Sc','Texas University'),
(101,'Mary Thomas','Logic System Design',77,'BS Computer Sc','University of Virginia'),
(221,'Srinivasan Nagendran','Mathematics',98,'BS Computer Sc','University of Virginia'),
(2691,'Kennete James','Set Theory',85,'BS Computer Sc','Texas University'),
(115,'Harry Davis','Advanced Mathematics',92,'BS Computer Sc','University of Virginia'),
(1134,'Shari Kraskow','Advanced Modelling techniques',79,'BS Computer Sc','Texas University'),
(221,'Srinivasan Nagendran','Artificial Intelligence',63,'BS Computer Sc','University of Virginia'),
(1134,'Shari Kraskow','Algorithm Analysis',88,'BS Computer Sc','Texas University'),
(2691,'Kennete James','Logic Systems',78,'BS Computer Sc','Texas University')
Once the data is setup in the table we can import it to a power pivot sheet and calculate the dense rank values as shown below
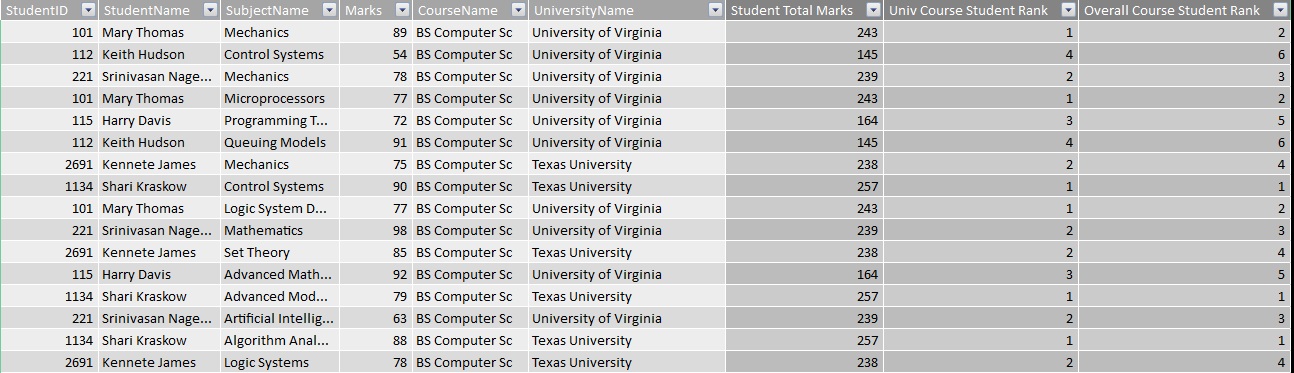
As you see from above we've three calculated column added to the powerpivot. The first calculated column calculates the consolidated marks for each student for each of courses within the university. This is used as a basis for calculating the subsequent columns ie student rank within a university and overall rank.
The DAX functions used will be as follows
Student Total Marks
The DAX expression used is
=SUMX(FILTER(StudentDetails,EARLIER(StudentDetails[StudentName])=StudentDetails[StudentName] && EARLIER(StudentDetails[CourseName])=StudentDetails[CourseName] && EARLIER(StudentDetails[UniversityName])=StudentDetails[UniversityName] ),[Marks])
Lets analyze the above expression. FILTER() function will return us a derived table after applying a set of filter conditions over an existing table in powerpivot data model. EARLIER() is a rowcontext function available in DAX which puts current row value in context and does comparison based on that.
So FILTER(StudentDetails,EARLIER(StudentDetails[StudentName])=StudentDetails[StudentName] && EARLIER(StudentDetails[CourseName])=StudentDetails[CourseName] && EARLIER(StudentDetails[UniversityName])=StudentDetails[UniversityName] ) will compare values of StudentName,CourseName and UniversityName values of the current row with rest of the rows of the table and returns a derived table of matching rows. SUMX() will apply summation over specified column of the table passed. So in this case SUMX calculates the sum of Marks column within each of the table subset determined by values of StudentName,CourseName and UniversityName.
In example above for Mary Thomas rows it will return Total Marks as 89 + 77 + 77= 243 which is the consolidated value across all rows for the student.
Univ Course Student Rank
Expression is as follows
=CALCULATE(DISTINCTCOUNT(StudentDetails[Student Total Marks])+1,FILTER(StudentDetails,EARLIER(StudentDetails[CourseName])=StudentDetails[CourseName] && EARLIER(StudentDetails[UniversityName])=StudentDetails[UniversityName] && EARLIER(StudentDetails[Student Total Marks])< StudentDetails[Student Total Marks]))
This expression makes use of the same derived table logic to get subset of table for each row based on its CourseName,UniversityName values matching with current row value and having Total Marks values < the Total Marks value in the table. So this will return all rows for same course and university and having Student Total Marks value greater than the Total Marks for current row ie students above current student in terms of performance for same course and university. Because this table has subject level data we need to take distinct of this to get one row per student consolidated. Adding 1 to that will give current rank position of student with respect to total marks scored with same Course,University subset. CALCULATE() function calculates the given aggregate (in this case DISTINCTCOUNT +1 ) over the specified derived table returned by FILTER expression.
Overall Course Student Rank
This is exactly similar to the above with the only difference being we consolidate marks over CourseName field alone without considering university to get the overall rank value.
The above DAX expressions used are analogous to the below T-SQL logic
SELECT *,
DENSE_RANK() OVER (PARTITION BY CourseName,UniversityName ORDER BY StudentTotalMarks DESC) AS UnivCourseStudentRank,
DENSE_RANK() OVER (PARTITION BY CourseName ORDER BY StudentTotalMarks DESC) AS OverallCourseStudentRank
FROM
(
SELECT *,
SUM(Marks) OVER (PARTITION BY StudentName,CourseName,UniversityName) AS StudentTotalMarks
FROM StudentDetails
)t
If you run the above query against the database table and check results it should exactly match what we got inside the powerpivot sheet as below

You may refer the below links for more information on the DAX functions
EARLIER
http://technet.microsoft.com/en-us/library/ee634551(v=sql.105).aspx
CALCULATE
http://technet.microsoft.com/en-us/library/ee634825(v=sql.105).aspx
FILTER
http://technet.microsoft.com/en-us/library/ee634966(v=sql.105).aspx
SUMX
http://technet.microsoft.com/en-us/library/ee634959(v=sql.105).aspx
No comments:
Post a Comment